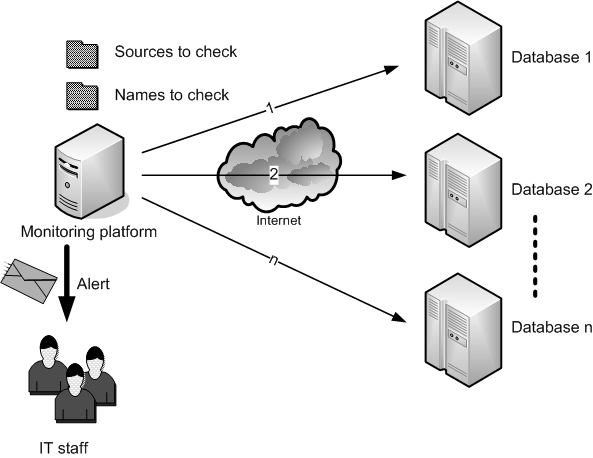
#! /usr/bin/perl
use strict;
use warnings;
my $version="0.1";
my %list=();
my %sources=();
my %email=();
my $archive="monitoring.archive";
sub LoadSources {
my ($file)=@_;
my $name="";
open(FILE,"<$file") or die "Cannot open sources file";
foreach my $line ( <FILE> ) {
chomp $line;
if ($line =~ m/^#/) {next;}
if ($line =~ m/^\[[A-Za-z0-9-]*\]/) {
$name=substr($line,1,length($line)-2);
$sources{$name}{name}=$name;
}
elsif ($line =~ m/\=/) {
$sources{$name}{$`}=$';
#We also insert some keys such as field_name so that's it's easier to find values
if ($line =~ m/field_[0-9]+\=/){
$sources{$name}{'field_'.$'}=substr($line,6,index($line,'=')-6);
}
}
}
close(FILE);
return %sources;
}
sub LoadList {
my ($file)=@_;
my $name=my $email="";
my $count=0;
open(FILE,"<$file") or die "Cannot open sources file";
david@sd-4257:~/tools$ more monitor.pl
#! /usr/bin/perl
use strict;
use warnings;
my $version="0.1";
my %list=();
my %sources=();
my %email=();
my $archive="monitoring.archive";
sub LoadSources {
my ($file)=@_;
my $name="";
open(FILE,"<$file") or die "Cannot open sources file";
foreach my $line ( <FILE> ) {
chomp $line;
if ($line =~ m/^#/) {next;}
if ($line =~ m/^\[[A-Za-z0-9-]*\]/) {
$name=substr($line,1,length($line)-2);
$sources{$name}{name}=$name;
}
elsif ($line =~ m/\=/) {
$sources{$name}{$`}=$';
#We also insert some keys such as field_name so that's it's easier to find values
if ($line =~ m/field_[0-9]+\=/){
$sources{$name}{'field_'.$'}=substr($line,6,index($line,'=')-6);
}
}
}
close(FILE);
return %sources;
}
sub LoadList {
my ($file)=@_;
my $name=my $email="";
my $count=0;
open(FILE,"<$file") or die "Cannot open sources file";
foreach my $line ( <FILE> ) {
if ($line =~ m/^\n/) {next;}
chomp $line;
if ($line =~ m/^#/) {next;}
$count++;
($name,$email)=split(/\t/,"$line");
${list}{$count}=$name;
${email}{$count}=$email;
}
close(FILE);
return %list;
}
sub LoadEmail {
my ($file)=@_;
my $name=my $email="";
my $count=0;
open(FILE,"<$file") or die "Cannot open sources file";
foreach my $line ( <FILE> ) {
if ($line =~ m/^\n/) {next;}
chomp $line;
if ($line =~ m/^#/) {next;}
$count++;
($name,$email)=split(/\t/,"$line");
${list}{$count}=$name;
${email}{$count}=$email;
}
close(FILE);
return %email;
}
sub FetchSourcesURL {
my $dir="/tmp";
foreach my $id_src (sort keys %sources) {
if (!GetHTML($id_src,$sources{$id_src}{url},$dir)){
SanitizeFile($id_src,$dir);
TrackNamesIn($id_src,$dir);
}
}
}
sub GetHTML {
my ($output,$page,$dir)=@_;
$page=quotemeta($page);
# Change following line with a perl call if you prefer
return `wget --quiet --output-document=$dir/$output --user-agent=Mozilla/4.0 --tries=1 $page`;
}
sub SanitizeFile {
# This function is used to insert "end of line" when page has
# been rendered by a script as a ugly bunch of code
my ($id_src,$dir)=@_;
my $temp=$id_src.".san";
open(FILE,"<$dir/$id_src") or die "Cannot open HTML file in READ mode";
open(SAN,">$dir/$temp") or die "Cannot open HTML file in WRITE mode";
foreach my $line ( <FILE> ) {
$line =~ s/<\/tr>/<\/tr>\n/ig;
$line =~ s/<tr *[0-9a-zA-Z_\#\:\;\=\'\" ]*>/<tr>\n/ig;
$line =~ s/<\/td>/<\/td>\n/ig;
$line =~ s/<br *\S*>/<br>\n/ig;
$line =~ s/\*+/\*/ig;
$line =~ s/\++/\+/ig;
$line =~ s/[^\\]\(/\\\(/ig;
$line =~ s/[^\\]\)/\\\)/ig;
print SAN $line;
}
close (FILE);
close (SAN);
`mv $dir/$temp $dir/$id_src`
}
sub TrackNamesIn {
my ($id_src,$dir)=@_;
my $tmp=my $lsb=my $lse=my $match=my $email="";
my $look_after= my $look_before=my $field_counter=0;
my %fields=();
open(FILE,"<$dir/$id_src") or die "Cannot open HTML file";
if ($sources{$id_src}{'look_after'}){ $look_after=1;}
if ($sources{$id_src}{'look_before'}){ $look_before=1;}
if ($sources{$id_src}{'line_separator_begin'}){
$lsb=$sources{$id_src}{'line_separator_begin'} ;
}
if ($sources{$id_src}{'line_separator_end'}){
$lse=$sources{$id_src}{'line_separator_end'} ;
}
foreach my $line ( <FILE> ) {
chomp $line;
if ($line =~ /^ *$/){
next;
}
if ($look_after==1){
$tmp=$sources{$id_src}{'look_after'};
if ($line =~ /$tmp/) {
$look_after=0;
}
else {next;}
}
if ($lsb ne ""){
if ($lsb =~ /$line/) {
$field_counter=0;
%fields=();
next;
}
}
if ($lse ne ""){
if ($lse =~ /$line/) {
# Next line mean we found structured data during source crawl
if ($match){
Alert($email,$match,$sources{$id_src}{name},%fields);
$match="";
}
next;
}
}
# WORKING ON THE LINE FIELDS
$field_counter++;
if ($sources{$id_src}{'field_'.$field_counter}){
if ($sources{$id_src}{'field_'.$field_counter} eq "any"){
next;
}
$line =~ s/$sources{$id_src}{'field_'.$field_counter.'_before'}//;
$line =~ s/$sources{$id_src}{'field_'.$field_counter.'_after'}//;
$fields{$sources{$id_src}{'field_'.$field_counter}}=$line;
if ($sources{$id_src}{'field_'.$field_counter} eq "name"){
foreach my $list_id ( keys %list){
if ($line =~ m/$list{$list_id}/i) {
$match=$line;
$email=$email{$list_id};
}
}
}
}
# FOR sources from where no field have been defined
else {
foreach my $list_id2 ( keys %list){
if ($line =~ m/$list{$list_id2}/i) {
Alert($email{$list_id2},$line,$sources{$id_src}{name},,);
}
}
}
if ($look_before==1){
$tmp=$sources{$id_src}{'look_before'};
if ($line =~ /$tmp/) {
$look_before=0;
last;
}
else {next;}
}
}
close (FILE);
}
sub Alert {
my ($email,$line,$source,%fields)=@_;
my $message="Matching in :".$line."\n\n";
my $archive_message="";
my $seen=0;
foreach my $field_id ( keys %fields){
$message.=$field_id. " = ".$fields{$field_id}."\n";
}
if (-e $archive){
open(FILE,"<$archive") or die "Cannot open archive file in READ mode";
foreach my $data (<FILE>){
if ($data =~ /^\:\:\:\:$/){
if ($archive_message eq $message){
$seen=1;
last;
}
$archive_message="";
next;
}
$archive_message.=$data;
}
close(FILE);
}
if ($seen==0) {
open(FILE,">>$archive") or die "Cannot open archive file in WRITE mode";
print ( FILE $message."\:\:\:\:\n");
close(FILE);
# CHANGE THE MAIL PROGRAM IF YOU WANT
eval{
open (MAIL, "|/usr/sbin/sendmail -t -oi ");
print MAIL ("To: $email\n");
print MAIL ("From: monitoring\@bizeul.org\n");
print MAIL ("Subject: Monitoring alert in $source\n\n");
print MAIL ("$message");
close (MAIL);
};
}
}
sub Usage {
print "\n\n\tusage : $0 <list> <source>\n\n";
}
if (@ARGV != 2){
print "Argument missing\n";
Usage();
exit;
}
print "**********************************\n";
print "* monitor.pl *\n";
print "* *\n";
print "* version : ".$version." *\n";
print "* credit : David Bizeul *\n";
print "**********************************\n";
my $list=shift;
my $sources=shift;
%list=LoadList($list);
%email=LoadEmail($list);
%sources=LoadSources($sources);
FetchSourcesURL();
# This file is used for listing sources from where data will be analyzed
# Mandatory options are the net ones
# [Name used]
# url=the location from where we collect the data
# Other options are optional even if it's better to use them for speed and monitoring visibility
# look_after=optional - Use it if you wish to ask to process after a special word
# look_before=optional - Use it if you wish to ask to process before a special
# line_separator_begin=optional - Use to separate fields
# line_separator_end=optional - Use to separate fields
# You have to use line_separator if you intend to use fields
# field_n=optional - Use it and its separator to tell the monitoring prog what kind of data you intend to s
ee in this field
[Internet-Defense]
url=http://phishery.internetdefence.net/data
look_after=Archive Contents
look_before=end content
line_separator_begin=<tr>
line_separator_end=</tr>
field_1=any
field_1_before=<td>
field_1_after=</td>
field_2=name
field_2_before=<td><a href=\"[0-9]*\">
field_2_after=</a></td>
field_3=type
field_3_before=<td><a href=\"\S+\">|<td>
field_3_after=</a></td>|</td>
field_4=title
field_4_before=<td><a href=\"[0-9]*\">
field_4_after=</a></td>
field_5=date
field_5_before=<td><a href=\"[0-9]*\">
field_5_after=</a></td>
field_6=hour
field_6_before=<td><a href=\"[0-9]*\">
field_6_after=</a></td>
[Castlecops]
url=http://www.castlecops.com/modules.php?name=Fried_Phish&fp=phish
look_after=status: confirmed phish
look_before=SiteSearch Google
line_separator_begin=<tr>
line_separator_end=</tr>
field_1=id
field_1_before=<td><a href=\"\S+\">
field_1_after=</a></td>
field_2=name
field_2_before=<td>
field_2_after=</td>
field_3=entry
field_3_before=<td *\S*>
field_3_after=</td>
field_4=reporter
field_4_before=<td>
field_4_after=</td>
field_5=timestamp
field_5_before=<td>
field_5_after=</td>
field_6=topic
field_6_before=<td><a href=\"\S+\">
field_6_after=</a></td>
[PhishTank]
url=http://www.phishtank.com/phish_search.php?verified=u&active=y
[Zone-H]
url=http://www.zone-h.org/component/option,com_attacks/Itemid,43
[Millersmiles]
url=http://www.millersmiles.co.uk